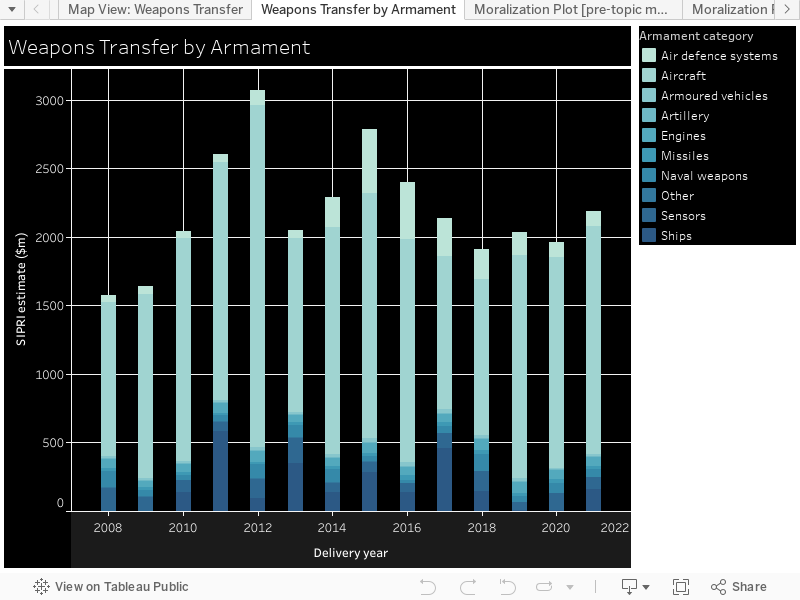
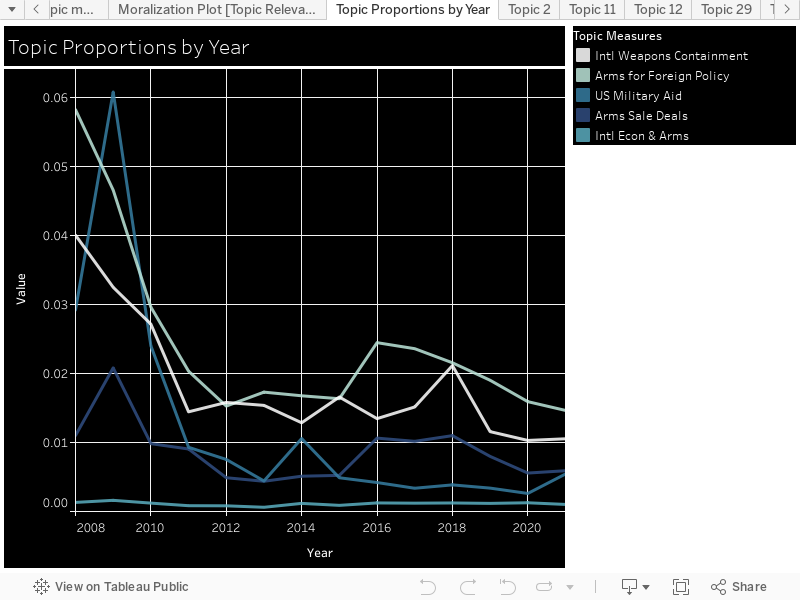
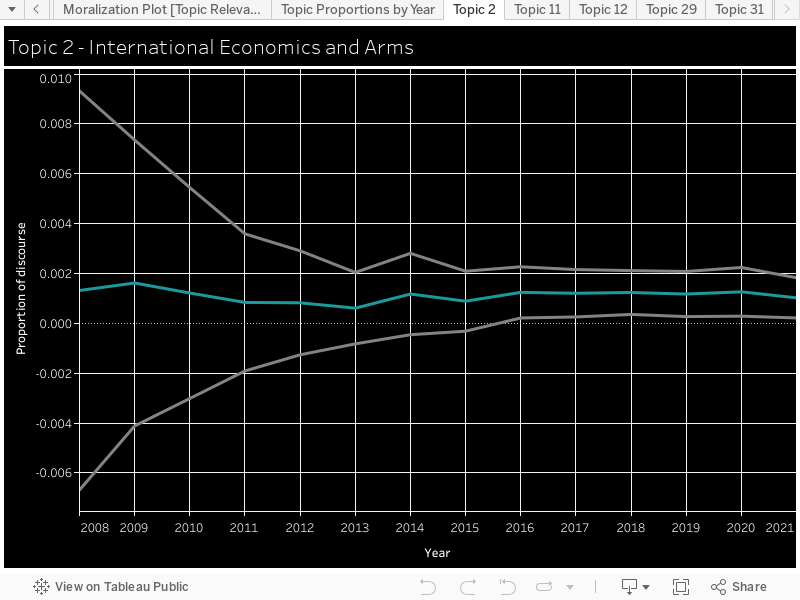
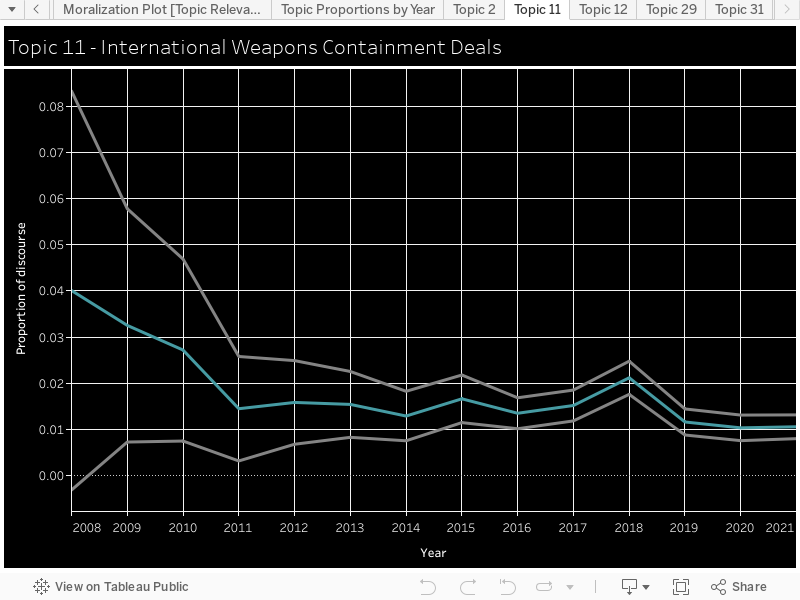
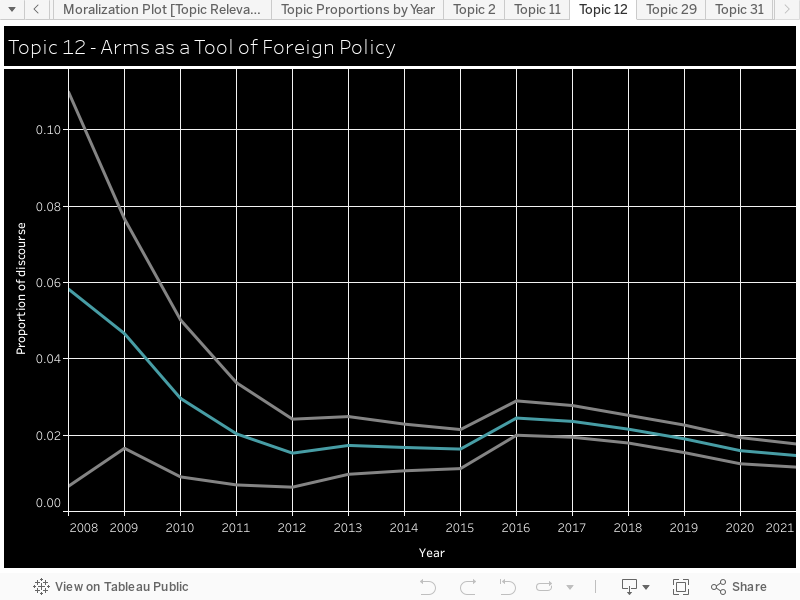
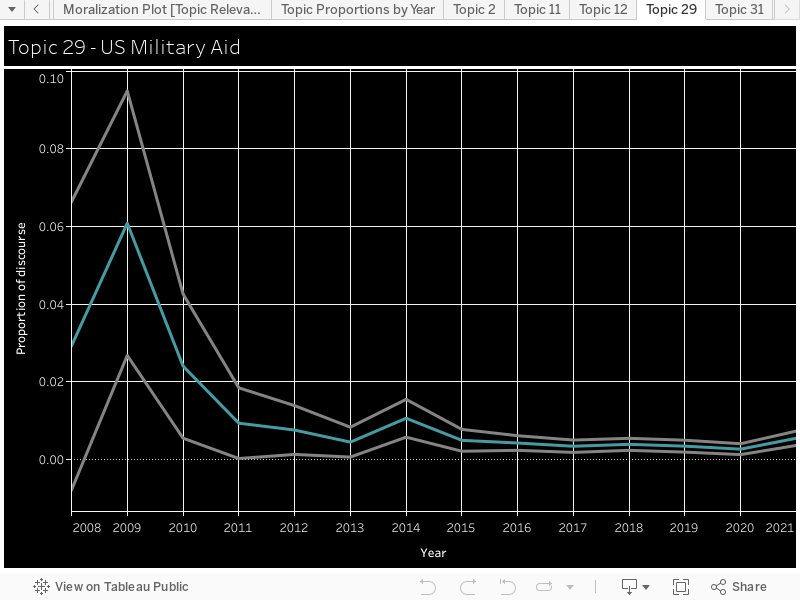
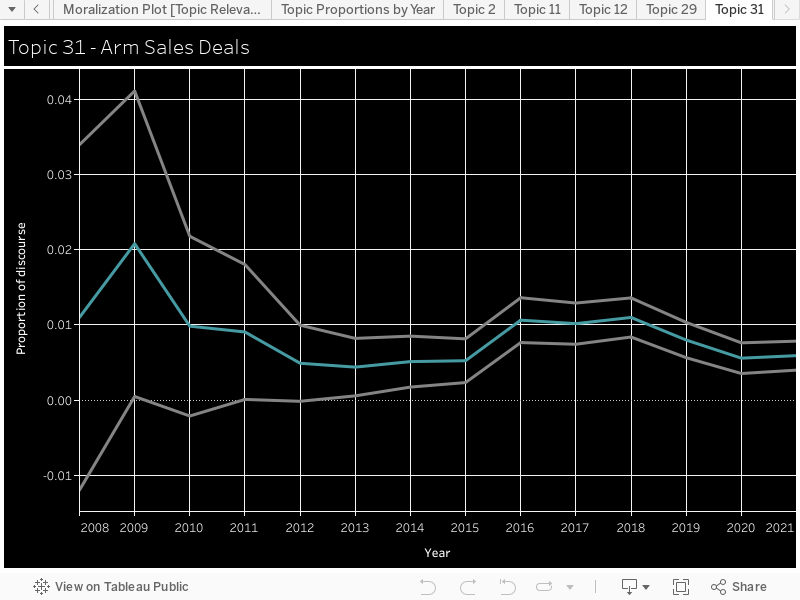
Moralization: We used the Moral Foundations Reddit Corpus described
here for training a classifier to identify moralized content in our social media dataset. The first 52,269 entries were used as training and evaluation data with a randomized 80,20 split. The remaining 8,958 data points were used as a test set. We considered the “Non-Moral” label as 0 and any other label as 1 to simplify the task to a binary classification. A majority rule was used to adjudicate between the three annotators across the training and evaluation data points.